2016 ObjectOrientedについて
Table of Contents
- 1. オブジェクト指向に至る軌跡
- 2. オブジェクト指向あれこれ
- 3. オブジェクト指向に至るまで (まとめのまとめ)
- 4. Joe Armstrongのオブジェクト指向はクソだ!
- 5. Strategic Choice を読もう
- 6. 記事一覧
- 7. 構造化プログラミング
- 8. パルナスの規則
- 9. 抽象データ型 - Strategic Choice
- 10. オブジェクト指向の本懐 - Strategic Choice
- 11. オブジェクト指向設計原則 - Strategic Choice
- 12. プログラミング原則 Unix思想 - Strategic Choice
- 13. ソフトウェア開発の真実とウソ - Strategic Choice
- 14. ソフトウェア開発原則一覧 - Strategic Choice
- 15. 七つの設計原理 - Strategic Choice
- 16. 漏れのある抽象化の法則 - Strategic Choice
- 17. オブジェクト指向プログラミングとは
ホーム / 講義 / ruby / OO / poker開発 / emacs / meta-ruby / note / github-repos / svn-repos 2015 /
1 オブジェクト指向に至る軌跡
1.1 オブジェクト指向以前
オブジェクト指向プログラミング、あるいはオブジェクト指向言語は、 それに至るまでの様々なアイデアを統合し、再編され、また現実 的な制約の中で歪みながら生まれてきたものだったりする。
プログラミングパラダイムは, 現実世界のプログラミングという人間活動の中で生じた 課題をどのように整理していくかという中で生まれてきた。
ソフトウェア危機
ソフトウェア危機 (wikipedia) とは
1960年代の後半、コンピュータが進歩するにつれて、より複雑 なソフトウェアが求められ始める時代、その複雑さをコントロールするた めの道具やアイデアはあまり多くなかった。
プロジェクトは、複雑化する一方なのに、管理手法もなければ、データ型 は基本的な数値でしかなく、変数はメモリアロケーションそのものだった。
また、プログラムの流れは、gotoやjump命令のようにプログラムカウンタ を直にコントロールする抽象度の低いもので制御されることが多かった。
プログラムはフローチャートで記述され、それをマシン語としてパンチす るといったプロジェクトX的な世界のことを考えれば、その理解が正しいの かもしれない。
なんにせよ、そういった当時の人からすると逼迫していたが、今から見る となんとも牧歌的な世界観の中で、構造化プログラミングという概念が生 まれる。
構造化プログラミング
ダイクストラは構造化プログラミングを提案した
ときどき、勘違いされているが構造化プログラミングとは「手続き型言語」 のことでもなければ「gotoを使わないプログラミング」のことでもない。
Todo 構造化プログラミングとは
- 構造化プログラミングではプログラミング言語が持つステートメントを 直接使ってプログラムを記述するのではなく、
- それらを抽象化したステートメントを持つ仮想機械を想定し、
- その仮想機械上でプログラムを記述する。
- 普通、抽象化は1段階ではなく階層的である。
- 各階層での実装の詳細は他の階層と隔離されており、
- 実装の変更の影響はその階層内のみに留まる(Abstract data structures)。
- 各階層はアプリケーションに近い抽象的な方から土台に向かって順 序付けられている。
- この順序は各階層を設計した時間的な順番とは必ずしも一致しない
つまり、現代風に言い換えると「レイヤリングアーキテクチャ」のよう なもので、ある土台の上にさらに抽象化した土台をおき、その上にさら に・・・というようにプログラムをくみ上げていく考え方のことだ。
これは、現在のプログラミングにおいても当たり前となっている考え方 だ。
だから、我々は、ひとつのアーキテクチャないし関数の中で異なる抽象 化レイヤの実装を同居することをさける。
一方、耳目を集めやすいgoto文有害論とともに構造化技法の一部である 構造化定理(任意のフローチャートは、for文とif文で記述できる)が注目 され、手続き型プログラミング言語を現代の形に押し上げていった。
モジュラプログラミング
こういった背景のなか、プログラムは大きく複雑になり続ける。至極自然 な流れとして、それを分割しようとしていく。
凝集度と結合度
モジュールの分割には、大きな指針がなかった。現在でもやろうと思え ば全然関係のない機能を1つのモジュールに詰め込むことはできる。
熟練したプログラマとそうでないプログラマで、作り出すモジュールの 品質は違う。その品質の尺度として、凝集度と結合度という概念がしば らくして生まれた。
結合度:よいコラボレーションとわるいコラボレーションを定義した https://ja.wikipedia.org/wiki/%E7%B5%90%E5%90%88%E5%BA%A6
凝集度:よい機能群のまとめ方とわるい機能のまとめ方を定義した https://ja.wikipedia.org/wiki/%E5%87%9D%E9%9B%86%E5%BA%A6
これらは「関心の分離」を行うためにどのようにするべきかという指針でもあった。 https://ja.wikipedia.org/wiki/%E9%96%A2%E5%BF%83%E3%81%AE%E5%88%86%E9%9B%A2
この「関心」とはそのモジュールの「責任」「責務」と言い換えてもい いかもしれない。この責任とモジュールが一致した状態にできるとその モジュールは凝集度が高く、結合度を低くすることができる。
それぞれ悪い例と良い例を見ていき、「責任」「責務」の分解とは何か をとらえていこう。
悪い結合、良い結合
悪い結合としては、あるモジュールが依存しているモジュールの内部デー タをそのまま使っていたり(内容結合)、同じグローバル変数(共通結 合)をお互いに参照していたりというようなつながり方だ。
こうなってしまうとモジュールは自分の足でたっていられなくなる。つ まり、片方を修正するともう片方も修正せざるをえなくなったり、予想 外の動作を強いられることになる。
逆に良い結合としては、定められたデータの受け渡し(データ結合)やメッ セージの送信(メッセージ結合)のように内部構造に依存せず、情報の やり取りが明示的になっている状態を言う。
これはまさにカプセル化とメッセージパッシングのことだよね、と思っ た方は正しい。オブジェクト指向は良い結合を導くために考えだされた のだから。
悪い凝集、良い凝集
凝集度が低い状態とは,つまり悪い凝集とは,何か,
- 暗合的凝集
- アトランダムに選んできた処理を集めたモジュールは 悪い。何を根拠に集めたのかわからないものも悪い凝集だ。
- 論理的凝集
- 論理的に似ている処理だからという理由だけで集めて はいけない。
たとえば、入出力の処理だからといって、
function open(type,name){
switch(type){
case "json": ... break;
case "yaml": ... break;
case "csv" : ... break;
case "txt" : ... break;
:
}
return result;
}
openという関数にif文やswitch文を大量に入れて、あらゆるopen処理を まとめた関数をイメージしてもらいたい。(その論理的な関係を一つの 記述にまとめたいと思うこと自体は悪い発想じゃないが、同じ場所に書 くことで、もっと大事なデータとの関係が危うくなってしまう。その矛 盾をうまく解決するのが同じメッセージをデータ構造ごとに異なる解釈 をさせるポリモーフィズムだ。)
そういった種類のものがメンテナンスしづらいというのはイメージしや すいだろう。
- 時間的凝集
- 他にも同じようなタイミングで実施されるからといっ て、モジュール化するのもの問題がある。たとえば、 initという関数の中ですべてのデータ構造の初期化を するイメージをしてほしい。
一方、良い凝集とはなんなのか、それは
- 通信的凝集
- とあるデータに触れる処理をまとめることであるとか、
- 情報的凝集
- 適切な概念とデータ構造とアルゴリズムをひとまとめ にすること。
- 機能的凝集
- それによって、ひとつのうまく定義されたタスクをこ なせるように集めることである。
状態と副作用の支配
よいモジュール分割とはなにか
それは、処理とそれに関連するデータの関係性を明らかにして支配し ていくことの重要性だ。
できれば、完全にデータの存在を隠蔽できてしまえると良いが、現実 のプログラムではそうは行かない場合も多い。
こういった実務プログラミングの中で何が難しいかというと、それが状 態と副作用を持つことだ。
たとえば、
function add(a,b){
return a+b;
}
このような副作用を持たない関数はテストもしやすく、バグが入り込む隙が少ない。 たとえば、計算機のレジスタ機能をこの関数に導入し、
var r = 0;
function add(a,b){
r = a+ (isUndefined(b)||r)
return r
}
このようにすると途端に考慮するべき事柄が増える。関連する状態や副 作用を含めて、関数を大別すると次のようになる。
オブジェクト指向に至るモジュラプログラミングは、こういった状態や 副作用に対して,積極的に命名,可視化,粗結合化をしていくことで 「関心の分離」を実現しようとした。
たとえば、現在でもC言語のプロジェクトなどでは,構造体とそれを引 数とする関数群ごとにモジュールを分割し,大規模なプログラミングを 行っている。構造体と関数群
typedef struct {
:
} Person;
void person_init(person*p,...){
:
}
char * person_get_name(person *p){
:
}
void person_set_name(person *p,char *name){
:
}
よくあるのは、上記のように構造体の名前のprefixとしてつけ、構造体 のポインタを第一引数として渡す手法だ。
その名残なのか、正確なところはよく知らないが、pythonやperlのオブ ジェクト指向では、自分自身を表すデータが、第一引数として関数に渡 される。
class Person(object):
def __init__(self, a, b):
self.a = a
self.b = b
package Person {
sub new(){
my ($class,$a,$b) = @_;
my $self = bless{},$class;
$self->init($a,$b);
return $self;
}
sub init {
my ($self,$a,$b) = @_;
$self->{a} = $a;
$self->{b} = $b;
}
}
あくまで関数の純粋性を犠牲にしないように発展を続けた関数型プログ ラミングと、状態や副作用をデータ構造として主役にしていった手続き 型プログラミングの分かれ目として理解すると面白い。
抽象データ型
よいモジュール化の肝は、状態と副作用を隠蔽し、データとアルゴリズム をひとまとめにすることだった。
それらを言語的に支援するために抽象データ型という概念が誕生した。
抽象データ型は、今で言うクラスのことだ。すなわちデータとそれに関連 する処理をひとまとめにしたデータ型のことだ。ようやくオブジェクト指 向の話に近づいてきた。ダイクストラの構造化プログラミングでは、デー タ処理をどのように抽象化するかが課題として残っていた。
また、データ型と実際のメモリアロケーションは別であるので、新たに変 数を定義するとデータの共有はしない。あるデータ型を実際に存在するメ モリに割り当てることをインスタンス化という。
抽象データ型のポイントは、その内部データへのアクセスを抽象データ型 にひもづいた関数でしか操作することができないという考え方だ。
これはつまり、たとえば、先ほどのC言語の例でいうと
//people.h
typedef struct {
//内部構造も公開している
} people;
void people_init(people *p,...);
char * people_get_name(people *p);
void people_set_name(people *p,char *name);
このままだと、構造体の内部構造も公開しているので、
people user;
user.age = 10;
printf("%d years old",user.age);
のように内部構造に直接アクセスできてしまう。C言語では、テクニック としてperson.h こちらを公開する
typedef struct sPerson person; void person_init(person *p,...); char * person_get_name(person *p); void person_set_name(person *p,char *name);
//people_private.h こちらはモジュール内で利用する
#include "person.h";
struct sPerson {
// ここに内部構造
};
//非公開用関数
_person_private(person *p,....);
公開するヘッダと非公開のヘッダを分けることで、情報の隠蔽を行い抽象 データ型としての役目を成り立たせている。
抽象データ型の情報隠蔽とカプセル化
C言語の構造体であっても、ヘッダファイルの定義と実装を分けることで、 抽象データ型の内部構造を隠蔽することができたが、言語機能として外 部からのアクセスに対する制限を明示できるようにサポートした。カプ セル化やブラックボックス化というのは情報隠蔽よりも広い概念ではあ るが、これらの機能によって、「悪い結合」を引き起こさないようにし ている。
JavaやC#などのアクセス修飾子がそれにあたる。
PerlやJavaScriptなどアクセス修飾子の無い言語では、公開と非公開を 明確に区別せず、_privateMethodのようにアンダースコアを先頭につけ ることで、擬似的に公開と非公開を区別する。
いずれにしても、ポイントは抽象化されたデータを取り扱うレイヤは、 抽象化されていない生の階層を直接触ることがないという階層化の考え 方だ。
これによって、複雑化した要求を抽象化の階層を定義していくという現 代的なプログラミングスタイルが確立した。
1.2 オブジェクト指向?
最初のオブジェクト指向言語は、1960年代に出現したSimulaという言語だ。
これはシミュレーション記述のために作られた言語であったが、後に汎用言 語となった。
オブジェクト、クラス(抽象データ型)、動的ディスパッチ、継承が既にあ り、ガーベジコレクトまで実装されていたらしい。汎用言語としてそこまで はやることはなかったが、これらの優れたコンセプトは今現在まで生き残っ ている。
Simulaの優れたコンセプトをもとに,2つの,今でも使われている,C言語 拡張が生まれた。
一つはC++。もう一つはObjective-Cである。
C言語はとても実際的なものだったので、それにプリプロセッサの形で優れ たコンセプトを輸入しようとしたのは当然の成り行きといえばそうだ。
SimulaのコンセプトをもとにSmalltalkという言語というか環境が爆誕した。
Smalltalkは、Simulaのコンセプトに「メッセージング」という概念を加え、 それらを再統合した。Smalltalkはすべての処理がメッセージ式として記述 される「純粋オブジェクト指向言語」だ。
そもそもオブジェクト指向という言葉はここで誕生した。
オブジェクト指向という言葉の発明者であるアランケイは後に「オブジェク ト指向という名前は失敗だった」と述べている。メッセージングの概念が軽 視されて伝わってしまうからだという。
何にせよ、このSmalltalkの概念をもとにC言語を拡張したのがObjective-C だ。
1.3 Simula & C++のオブジェクト指向
C++の作者であるビャーネ・ストロヴストルップは、オブジェクト指向を 「『継承』機構と『多態性』を付加した『抽象データ型』のスーパーセット」 として整理した。
C++ではメソッドのことをメンバー関数と呼ぶ。これはSimulaがメンバープ ロシージャと読んでいるところに由来する。メソッドは、Smalltalkが発明 した用語だ。
どの処理を呼び出すか決めるメカニズム
さて、継承と多態を足した抽象データ型といっても、なんだか良くわからない。
特に多態がいまいちわかりにくい。オブジェクト指向プログラミングの説明で
string = number.StringValue string = date.StringValue
これで、それぞれ違う関数が呼び出されるのがポリモーフィズムですよと 呼ばれる。
これだけだとシグネチャも違うので、違う処理が呼ばれるのも当たり前に 見える。
では、こう書いてみたらどうか
string = stringValue(number) // 実際にはNumberToStringが呼ばれる string = stringValue(date) // 実際にはDateToStringが呼ばれる
このようにしたときに、すこし理解がしやすくなる。引数の型によって呼 ばれる関数が変わる。こういう関数を polymorphic (poly-複数に morphic- 変化する) な関数という。
これをみたときに"関数のオーバーロード"じゃないか?と思った人は鋭い。 https://ja.wikipedia.org/wiki/%E5%A4%9A%E9%87%8D%E5%AE%9A%E7%BE%A9
多態とは異なる概念とされるが、引数によって呼ばれる関数が変わるとい う意味では似ている。しかし、次のようなケースで変わってくる。
function toString(IStringValue sv) string {
return StringValue(sv)
}
IStringValueはStringValueという関数を実装しているオブジェクトを表す インターフェースだ。これを受け取ったときに、関数のオーバーロードで は、どの関数に解決したら良いか判断がつかない。関数のオーバーロード は、コンパイル時に型情報を付与した関数を自動的に呼ぶ仕組みだからだ。
stringValue(number:Number) => StringValue-Number(number)
stringValue(date :Date) => StringValue-Date(date)
function toString(IStringValue sv) string {
return StringValue(sv) => StringValue-IStringValue (無い!)
}
それに対して、動的なポリモーフィズムを持つコードの場合、次のように 動作してくれるので、インターフェースを用いた例でも予想通りの動作を する。
function StringValue(v:IstringValue){
switch(v.class){ //オブジェクトが自分が何者かということを知っている。
case Number: return StringValue-Number(number)
case Date : return StringValue-Date(date)
}
}
このようにどの関数を呼び出すのかをデータ自身に覚えさせておき、実行 時に探索して呼び出す手法を 動的分配*,*動的ディスパッチ と呼ぶ。
このように動的なディスパッチによる多態性はどのような意味があるのか。
それはインターフェースによるコードの再利用と分離である。
特定のインターフェースを満たすオブジェクトであれば、それを利用した コードを別のオブジェクトを作ったとしても再利用できる。
これによって、悪い凝集で例に挙げた論理的凝集をさけながら、 汎用的な処理を記述することができるのだ。
オブジェクト指向がはやり始めた当時は、再利用という言葉が比較的バズっ たが、現在的に言い換えるなら、インターフェースに依存した汎用処理と して記述すれば、結合度が下がり、テストが書きやすくなったり、仕様変 更に強くなったりする。
動的ディスパッチ
動的ディスパッチのキモは、オブジェクト自身が自分が何者であるか知っ ており、また、実行時に関数テーブルを探索して、どの関数を実行する かというところにある。SimulaもC++もvirtualという予約語を用いて、 仮想関数の動的分配をすることを宣言できる。
/*
Vtable for B1
B1::_ZTV2B1: 3u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI2B1)
16 B1::f1
Class B1
size=16 align=8
base size=16 base align=8
B1 (0x7ff8afb7ad90) 0
vptr=((& B1::_ZTV2B1) + 16u)
*/
class B1 {
public:
void f0(){}
virtual void f1(){}
char before_b0_char;
int member_b1;
};
/*
Class B0
size=4 align=4
base size=4 base align=4
B0 (0x7ff8afb7e1c0) 0
*/
class B0{
private:
void f(){};
int member_b1;
};
このようにデータ自身にvtable(仮想関数テーブル)へのポインタを埋め込んであり、 それをたどることで解決する。
逆にvirtual宣言をしなければ、仮想関数テーブルをたどるというオーバー ヘッドなしに関数を呼ぶことができる。Javaでは、デフォルトでvirtual 宣言されているのと等価に動的なディスパッチが行われる。C++やC#では、 動的ディスパッチのコストを必要なときにしか利用しないために(ゼロオー バーヘッドポリシー)、virtual宣言を明示的にする必要がある。
objective-Cも同様であるが、関数ポインタを直に取得することでこのオー バーヘッドを回避することができる。
//objectivce-c.m SEL selector = @selector(f0); IMP p_func = [obj methodForSelector : selector ]; // p_funcを保持しておいて、繰り返しなどで : pfunc(obj , selector); // pfunc使うと、探索コストを減らせる。 // 何か重要でない限りする必要はない。
疑似コードで、この動的なディスパッチを表現するとこのようになる。
//動的ディスパッチの疑似コード
var PERSON_TABLE = {
"getName" : function(self){return self.name},
};
var object = {
_vt_ : PERSON_TABLE, // 自分が何ができるか教える
name : "daichi hiroki"
};
// メソッドを動的に呼び出す
function methodCall(object,methodName){
// オブジェクト自身を第一引数として束縛する
return object._vt_[methodName](object)
}
methodCall(object,"getName");
こうなってくると、多態を実現するためには、3つの要素が必要だとわかる。
- データに自分自身が何者か教える機能
- メソッドを呼び出した際にそれを探索する機能
- オブジェクト自身を参照できるように引数に束縛する機能
あとからオブジェクト指向的機能を追加したperl5の例が、これらを端的 に追加しているので見ていこう。
package Person;
sub new {
my($class,$ref) = @_;
#リファレンスとパッケージを結びつけるbless関数
# $classはPersonパッケージを表す
return bless( $object, $ref );
}
sub get_name{
my ($self) = @_;
$self->{name};
}
#メソッドの動的な探索と第一引数に束縛する->アロー演算子
my $person = Person->new({ name => "daichi hiroki"});
$person->get_name;
このなかで、bless関数はリファレンスに対して、リファレンス自身が 「関数を探索するべきモジュールはここですよ。」と教えている。 (blessは祝福するという意味。パッケージのご加護が守護霊みたいにくっ つくイメージ。)
また->演算子を使うことで、自動的に探索と呼び出しを実現している。
あと付けでOOP機能を足そうというときに、たった二つの機能で多態を実 現したPerl5のアプローチにはたぐいまれなセンスを感じる。
継承と委譲
さて、SimulaとC++がもたらした最後の要素は継承だ。継承は、あるク ラスの機能をもったまま、別の機能を追加したもう一つのクラスを作る 仕組みだ。
まずはデータだけで考えてみよう。 生徒と先生の管理をしたいというときに、 二つに共通しているデータ構造は名前、性別、年齢であり、 生徒は追加して、学科と年次を管理し、 先生は追加して、専門と月収を管理したいとする。
typedef struct {
int age;
int sex;
char *name;
} Person;
typedef struct {
People people;
int grade;
int study:
} Student;
typedef struct {
People people;
int field;
int salary;
} Teacher;
Teacher t;
t.people.age = 10;
とするとこのように構造体に構造体を埋め込むことで、共通するデータ 構造を持つことができる。
これに処理を追加する場合、次のようにするだろう。
char * person_get_name(Person *self) {
return self->name;
}
char * teacher_get_name(Teacher *self){
return person_get_name((People *)self);
}
char * teacher_get_name_2(Teacher *self){
return person_get_name(&self.person);
}
Teacher *pt = teacher_alloc_init(30,MALE,"daichi hiroki",MATH,30);
teacher_get_name(pt);
このようにアップキャストして、埋め込んだ構造体内部にアクセスすることができる。 それか、埋め込んだ構造体をそのまま渡すなどして、処理の共通化を実現する。
しかし、これでは処理の共通化をするごとにその呼び出しコードを追加する必要がある。 これをうまく提供してくれるのが 継承機能だ。
public/protectedなメンバー関数やメンバー変数に対して、継承関係をたどって 探すことができる。
そのため
Teacher *t = new Teacher; t->get_name; // Teacher自体に宣言がなくても、Peopleクラスを探索してくれる。
のように書くことができる。
また、
string nameFormat(People *p) {
return sprintf("%s(%d) %s",p->get_name,p->get_age,(p->get_sex == MALE) ? "男性" :"女性");
}
というような関数があったときに、
Person *p = new Person; Student *s = new Student; Teacher *t = new Teacher; nameFormat(p); nameFormat(s); nameFormat(t);
Person自身かそのサブクラスであれば、共通の処理を利用することができる。
この継承関係を言語機能として提供するためにperl5では、もう一つの機能を追加する。 それが@ISAだ。
package Person;
sub get_name{"person"}
package Student;
# @ISAにパッケージを追加するとblessされたパッケージに関数がなかった場合にそちらを探索に行く
our @ISA = qw/Person/;
package Teacher;
our @ISA = qw/Person/;
このようにどこを探索するのかという情報だけ宣言できるようにすれば、 問題なく継承関係を表現することができる。
ちょうど、FQNで表記すると
@Teacher::ISA="Person"という表現になり、teacher is a personという関係が成り立っていることを表現している。
このときのメソッド探索を疑似コードで書くと次のようになる。 動的ディスパッチの疑似コード
var PERSON_TABLE = {
"getName" : function(self){return self.name}
};
var STUDENT_TABLE = {
"getGrade" : function(self){return self.grade},
"#is-a#" : PERSON_TABLE
};
var object = {
_vt_ : STUDENT_TABLE, // 自分が何ができるか教える
name : "daichi hiroki"
};
// メソッドを動的に呼び出す
function methodCall(object,methodName){
var vt = object._vt_;
// is-aを順番にたどってmethodを見つけて実行する
while(vt){
var method = vt[methodName];
if( method ) return method(object);
vt = vt["#is-a#"];
}
throw Error;
}
methodCall(object,"getName");
継承の代わりに委譲という手段を用いているプログラミング言語がある。 これはSimulaとC++の系譜とは少し違うが、動的ディスパッチの話をしたので 簡単に説明する。
これは、クラスベースのオブジェクト指向に対してプロトタイプベース のオブジェクト指向と呼ばれたりする。身近な例ではJavaScriptなどだ。
継承と委譲の違いは先ほどのC言語の例で言えば、すごく単純で埋め込む構造体が ポインタかそうでないかという違いくらいだ。
typedef struct {
int age;
int sex;
char *name;
} Person;
typedef struct {
Person* person;
int grade;
int study:
} Student;
typedef struct {
Person* person;
int field;
int salary;
} Teacher;
委譲は、探索先のオブジェクトを動的に書き換えることができる。
t->person = new Person;
疑似コードで言えば、 動的ディスパッチの疑似コード
var hogetaro = { getName : function(self){return self.name}, name : "hogetaro" };
var object = { prototype : hogetaro, // 次に探索するオブジェクトを決める name : "daichi hiroki" };
// メソッドを動的に呼び出す function methodCall(object,methodName){ // 最初は自分自身 var pt = object; // is-aを順番にたどってmethodを見つけて実行する while(pt){ var method = pt[methodName]; if( method ) return method(object); pt = pt._prototype_; } throw Error; }
methodCall(object,"getName"); object._prototype_ = { getName:function(){return "hello"}}; // プロトタイプは動的に書き換えることができる。 methodCall(object,"getName");
このようになる。 こうやって、prototypeを順番に追って検索していくのをjavascriptではプロトタイプチェーンと読んでいる。luaであれば同じ役割をするのがmetatableというものがある。
こういった委譲によるメソッド探索は、動的継承とも呼ばれている。
このようにメソッドの動的な探索に対して、どのような機構をつけるのかというのが オブジェクト指向では重要な構成要素と言える。
rubyのmoduleやそのinclude,prepend、特異メソッド、特異クラスなどは まさにその例だ。
それらをjavascriptで疑似コード的に実装した例として、こちらを参照してもらいたい。 https://qiita.com/hirokidaichi/items/f653a843208971981c37
オブジェクト指向の要素
このようにオブジェクト指向のための機能は、
抽象データ型:データと処理をひもづける 抽象データ型:情報の隠蔽を行うことができる オブジェクト:データ自身が何者か知っている 動的多態:オブジェクト自身のデータと処理を自動的に探索する 探索先の設定:継承、委譲
ということになる。
1.4 Smalltalk & Objective-Cのオブジェクト指向
アランケイの「オブジェクト指向」の定義:
パーソナルコンピューティングに関わる全てを『オブジェクト』とそれらの間 で交わされる『メッセージ送信』によって表現すること
仮想機械としてのオブジェクト
アランケイの世界観の中では、メモリとCPUとそれに対する命令を持つ機械 をさらに抽象化するとしたら、それは同じくデータと処理と命令セットを もつ仮想機械で抽象化されるべきだと考えていた。
構造化プログラミングの中でダイクストラが仮想機械として階層 的に抽象化すべきだと言っていたこととかぶる。
オブジェクトは独立した機械と見なし,それに対してメッセージを送り、 自ら持つデータの責任は自らが負う。
Smalltalkの実行環境もまた仮想機械として作られている。
メッセージング
Smalltalkでメッセージ送信は下記のように記述する:
receiver message
Objective-Cであれば、C言語の中に次のように書く:
[receiver message] [receiver methodName:args1 with:args]
メッセージとは通信のアナロジーだ。アドレスさえ知っていれば、メッセー ジは自由に送れる。受信者(レシーバ)はメッセージを受け取っているにす ぎないので、その解釈は自由に行うことができる。
このメッセージらしさが出てくる特徴をいくつか紹介しよう。
動的な送信
メッセージ内容もまたオブジェクトにすぎないので、動的に作成し、送ることができる。 たとえば、rubyのObject#sendがその性質をそのまま表現している。
class A
def hello
p "hello"
end
end
a = A.new
# 動的にメソッドを作成
method = "he" + "ll" + "o"
# それを呼び出す
a.send(method)
メッセージ転送
受け取ったメッセージは、仮にメソッド定義がなかったとしても自由に取 り扱うことができる。
- rubyの method_missing や Objective-C の forwardInvocation がそれ にあたる。他にもPerlのAUTOLOADなど、最近の動的型言語には用意され ていることが多い。
- proxy.rb
class Proxy
def method_missing(name, *args, &block)
target.send(name, *args, &block)
end
def target
@target ||= []
end
end
Proxy.new << 1
'end'
たとえば、Proxyクラスをこのように定義してあげるとすべてのメッセージ を@targetのオブジェクトにそのまま転送してあげることができる。
非同期送信
ほとんどの言語でメッセージの結果を同期的に受け取るようになっている ので、意識しづらいが、メッセージというアナロジーである以上、それを 同期的に待ち受ける必要はない。
オブジェクト指向という言葉が意味していること
このようにメッセージパッシングというアナロジーを使うことで、様々な 性質がオブジェクト指向には加わることになった。
しかし、オブジェクト指向という言葉が意味しているのが、C++の再定義 したオブジェクト指向として理解されることで、このメッセージパッシン グの要素が意識されなくなってしまったため、前述したようにアランケイ はその命名が不適切だったと考えているらしい
https://www.infoq.com/jp/news/2010/07/objects-smalltalk-erlang
この記事は今までの議論の流れをふまえると、理解がしやすいと思う。 特に
私は、オブジェクト指向プログラミングというものに疑問を持ち始めまし た。Erlangはオブジェクト指向ではなく、関数型プログラミング言語だと 考えました。そして、私の論文の指導教官が言いました。「だが、あなた は間違っている。Erlangはきわめてオブジェクト指向です。」 彼は、オ ブジェクト指向言語はオブジェクト指向ではないといいました。これを信 じるかどうかは確かではありませんでしたが、Erlangは唯一のオブジェク ト指向言語かもしれないと思いました。オブジェクト指向プログラミング の3つの主義は、メッセージ送信に基づいて、オブジェクト間で分離し、 ポリモーフィズムを持つものです。
1.5 まとめ
- オブジェクト指向も構造化プログラミングも問題の抽象化で同じことを見ていた。
- C++はSimulaからモジュール化や抽象データ型、動的多態といった良い性質を採用した。
- 一方、SmalltalkはSimulaの着想をメッセージとオブジェクトという概念 で統合した。それによって、様々な動的な性質を現在の言語にもたらして きた。
- また、メッセージパッシングという概念は、本質的には現在注目を浴びて いる Actor や CSP のような並行モデルと似通っており、興味深い。
1.6 あとがき
少しはオブジェクト指向という考え方の背景が見えてきて、それがより良い 設計やコーディングにつながればうれしいです。
この説明は、オブジェクト指向の説明の本流ではない、いわば傍流的なもの ではありますが、より実際的で、より技術的理解を必要とするものなので、 初学者向けではなかったかと思います。ですが、これを理解することで、様々 な言語機能の背景を推察することができ、バラバラの事柄が有機的につなが ることを期待しています。
2 オブジェクト指向あれこれ
オブジェクト指向あれこれ https://d.hatena.ne.jp/asakichy/20090428/1240878836
アジャイル設計と5つの原則 - かまずにまるのみ。 https://tdak.hateblo.jp/entry/20130703/1372842149
オブジェクト指向の法則集 - Qiita https://qiita.com/kenjihiranabe/items/9eddc70e279861992274
オブジェクト指向の本懐 - Strategic Choice https://d.hatena.ne.jp/asakichy/20090421/1240277448
3 オブジェクト指向に至るまで (まとめのまとめ)
3.1 オブジェクト指向に至るまで
ソフトウェア危機
コンピュータが進歩するにつれて、より複雑なソフトウェアが求められ始める その複雑さをコントロールするための道具やアイデアが不足
プロジェクト管理手法もなければ、 抽象度の低いデータ型,変数,制御構造
構造化プログラミング
つまり、現代風に言い換えると「レイヤリングアーキテクチャ」のよう なもので、ある土台の上にさらに抽象化した土台をおき、その上にさら に・・・というようにプログラムをくみ上げていく考え方のことだ。
だから、我々は、ひとつのアーキテクチャないし関数の中で異なる抽象 化レイヤの実装を同居することをさける。
モジュラプログラミング
大きく複雑になるプログラムの分割
凝集度と結合度
結合度:よいコラボレーションとわるいコラボレーションを定義した https://ja.wikipedia.org/wiki/%E7%B5%90%E5%90%88%E5%BA%A6
凝集度:よい機能群のまとめ方とわるい機能のまとめ方を定義した https://ja.wikipedia.org/wiki/%E5%87%9D%E9%9B%86%E5%BA%A6
これらは「関心の分離」を行うためにどのようにするべきかという指針でもあった。 https://ja.wikipedia.org/wiki/%E9%96%A2%E5%BF%83%E3%81%AE%E5%88%86%E9%9B%A2
この「関心」とはそのモジュールの「責任」「責務」と言い換えてもい いかもしれない。この責任とモジュールが一致した状態にできるとその モジュールは凝集度が高く、結合度を低くすることができる。
悪い結合、良い結合
悪い結合としては、あるモジュールが依存しているモジュールの内部デー タをそのまま使っていたり(内容結合)、同じグローバル変数(共通結 合)をお互いに参照していたりというようなつながり方だ。
こうなってしまうとモジュールは自分の足でたっていられなくなる。つ まり、片方を修正するともう片方も修正せざるをえなくなったり、予想 外の動作を強いられることになる。
逆に良い結合としては、定められたデータの受け渡し(データ結合)やメッ セージの送信(メッセージ結合)のように内部構造に依存せず、情報の やり取りが明示的になっている状態を言う。
これはまさにカプセル化とメッセージパッシングのことだよね、と思っ た方は正しい。オブジェクト指向は良い結合を導くために考えだされた のだから。
悪い凝集、良い凝集
凝集度が低い状態とは,つまり悪い凝集とは,何か,
- 暗合的凝集
- アトランダムに選んできた処理を集めたモジュールは 悪い。何を根拠に集めたのかわからないものも悪い凝集だ。
- 論理的凝集
- 論理的に似ている処理だからという理由だけで集めて はいけない。
- 時間的凝集
- 他にも同じようなタイミングで実施されるからといっ て、モジュール化するのもの問題がある。たとえば、 initという関数の中ですべてのデータ構造の初期化を するイメージをしてほしい。
一方、良い凝集とはなんなのか、それは
- 通信的凝集
- とあるデータに触れる処理をまとめることであるとか、
- 情報的凝集
- 適切な概念とデータ構造とアルゴリズムをひとまとめ にすること。
- 機能的凝集
- それによって、ひとつのうまく定義されたタスクをこ なせるように集めることである。
状態と副作用の支配
よいモジュール分割とはなにか
それは、処理とそれに関連するデータの関係性を明らかにして支配し ていくことの重要性だ。
できれば、完全にデータの存在を隠蔽できてしまえると良いが、現実 のプログラムではそうは行かない場合も多い。
こういった実務プログラミングの中で何が難しいかというと、それが状 態と副作用を持つことだ。
オブジェクト指向に至るモジュラプログラミングは、こういった状態や 副作用に対して,積極的に命名,可視化,粗結合化をしていくことで 「関心の分離」を実現しようとした。
たとえば、現在でもC言語のプロジェクトなどでは,構造体とそれを引 数とする関数群ごとにモジュールを分割し,大規模なプログラミングを 行っている。
抽象データ型
よいモジュール化の肝
- 状態と副作用を隠蔽し、
- データとアルゴリズムをひとまとめにする
それらを言語的に支援するために抽象データ型という概念が誕生した。
抽象データ型は、今で言うクラス
- すなわちデータとそれに関連する処理をひとまとめにしたデータ型のこ とだ。
- 抽象データ型のポイントは、その内部データへのアクセスを抽象データ 型にひもづいた関数でしか操作することができないという考え方だ。
内部構造を隠し,型とインタフェースを公開する。
- 公開するヘッダと非公開のヘッダを分けることで、情報の隠蔽を行い抽象 データ型としての役目を成り立たせている。
抽象データ型の情報隠蔽とカプセル化
言語機能として外部からのアクセスを制限できるようにした。
カプセル化やブラックボックス化というのは情報隠蔽よりも広い概念で はあるが、これらの機能によって、「悪い結合」を引き起こさないよう にしている。
これによって、複雑化した要求を抽象化の階層を定義していくという現 代的なプログラミングスタイルが確立した。
3.2 オブジェクト指向?
simula
- オブジェクト、
- クラス(抽象データ型)、
- 動的ディスパッチ、
- 継承
- ガーベジコレクト
Simulaの優れたコンセプトをもとに,2つの,今でも使われている,C言語 拡張が生まれた。
一つはC++。もう一つはObjective-Cである。
SimulaのコンセプトをもとにSmalltalkという言語というか環境が爆誕した。
Smalltalkは、Simulaのコンセプトに「メッセージング」という概念を加え、 それらを再統合した。Smalltalkはすべての処理がメッセージ式として記述 される「純粋オブジェクト指向言語」だ。
そもそもオブジェクト指向という言葉はここで誕生した。
オブジェクト指向という言葉の発明者であるアランケイは後に「オブジェク ト指向という名前は失敗だった」と述べている。メッセージングの概念が軽 視されて伝わってしまうからだという。
何にせよ、このSmalltalkの概念をもとにC言語を拡張したのがObjective-C だ。
3.3 Simula & C++のオブジェクト指向
C++のオブジェクト指向
継承と多態性を付加した抽象データ型のスーパーセット
どの処理を呼び出すか決めるメカニズム
さて、継承と多態を足した抽象データ型といっても、なんだか良くわからない。
特に多態がいまいちわかりにくい。オブジェクト指向プログラミングの説明で
string = number.StringValue string = date.StringValue
これで、それぞれ違う関数が呼び出されるのがポリモーフィズムですよと 呼ばれる。
これだけだとシグネチャも違うので、違う処理が呼ばれるのも当たり前に 見える。
では、こう書いてみたらどうか
string = stringValue(number) // 実際にはNumberToStringが呼ばれる string = stringValue(date) // 実際にはDateToStringが呼ばれる
このようにしたときに、すこし理解がしやすくなる。引数の型によって呼 ばれる関数が変わる。こういう関数を polymorphic (poly-複数に morphic- 変化する) な関数という。
これをみたときに"関数のオーバーロード"じゃないか?と思った人は鋭い。 https://ja.wikipedia.org/wiki/%E5%A4%9A%E9%87%8D%E5%AE%9A%E7%BE%A9
多態とは異なる概念とされるが、引数によって呼ばれる関数が変わるとい う意味では似ている。しかし、次のようなケースで変わってくる。
function toString(IStringValue sv) string {
return StringValue(sv)
}
IStringValueはStringValueという関数を実装しているオブジェクトを表す インターフェースだ。これを受け取ったときに、関数のオーバーロードで は、どの関数に解決したら良いか判断がつかない。関数のオーバーロード は、コンパイル時に型情報を付与した関数を自動的に呼ぶ仕組みだからだ。
stringValue(number:Number) => StringValue-Number(number)
stringValue(date :Date) => StringValue-Date(date)
function toString(IStringValue sv) string {
return StringValue(sv) => StringValue-IStringValue (無い!)
}
それに対して、動的なポリモーフィズムを持つコードの場合、次のように 動作してくれるので、インターフェースを用いた例でも予想通りの動作を する。
function StringValue(v:IstringValue){
switch(v.class){ //オブジェクトが自分が何者かということを知っている。
case Number: return StringValue-Number(number)
case Date : return StringValue-Date(date)
}
}
このようにどの関数を呼び出すのかをデータ自身に覚えさせておき、実行 時に探索して呼び出す手法を 動的分配*,*動的ディスパッチ と呼ぶ。
このように動的なディスパッチによる多態性はどのような意味があるのか。
それはインターフェースによるコードの再利用と分離である。
特定のインターフェースを満たすオブジェクトであれば、それを利用した コードを別のオブジェクトを作ったとしても再利用できる。
これによって、悪い凝集で例に挙げた論理的凝集をさけながら、 汎用的な処理を記述することができるのだ。
オブジェクト指向がはやり始めた当時は、再利用という言葉が比較的バズっ たが、現在的に言い換えるなら、インターフェースに依存した汎用処理と して記述すれば、結合度が下がり、テストが書きやすくなったり、仕様変 更に強くなったりする。
動的ディスパッチ
動的ディスパッチのキモは、オブジェクト自身が自分が何者であるか知っ ており、また、実行時に関数テーブルを探索して、どの関数を実行する かというところにある。
こうなってくると、多態を実現するためには、3つの要素が必要だとわかる。
- データに自分自身が何者か教える機能
- メソッドを呼び出した際にそれを探索する機能
- オブジェクト自身を参照できるように引数に束縛する機能
継承と委譲
継承
委譲
このようにメソッドの動的な探索に対して、どのような機構をつけるのかというのが オブジェクト指向では重要な構成要素と言える。
rubyの module やその include, prepend、特異メソッド,特異クラスなどは まさにその例だ。
オブジェクト指向の要素
- 抽象データ型:データと処理をひもづける
- 抽象データ型:情報の隠蔽を行うことができる
- オブジェクト:データ自身が何者か知っている
- 動的多態:オブジェクト自身のデータと処理を自動的に探索する
- 探索先の設定:継承、委譲
ということになる。
3.4 Smalltalk & Objective-Cのオブジェクト指向
アランケイによるオブジェクト指向の定義:
パーソナルコンピューティングに関わる全てを『オブジェクト』とそれらの 間で交わされる『メッセージ送信』によって表現すること
仮想機械としてのオブジェクト
- アランケイの世界観
- コンピュータを抽象化するとしたら、データと処理と命令セットをも つ仮想機械で抽象化されるべき
- 構造化プログラミング
- 仮想機械として階層的に抽象化すべき
- オブジェクト指向
- オブジェクトを独立した機械と見なし、それに対してメッセージを送 り、自ら持つデータの責任は自らが負う。
Smalltalkの実行環境もまた仮想機械として作られている。
メッセージング
Smalltalkでメッセージ送信は下記のように記述する:
receiver message
メッセージングは通信。
- アドレスさえ知っていれば、メッセージは自由に送れる。
- レシーバはメッセージを受け取リ,その解釈はレシーバ自身が行う
このメッセージらしさが出てくる特徴をいくつか紹介しよう。
動的な送信
メッセージの内容もまたオブジェクトなので、動的に作成し送ることができる。
class A
def hello
p "hello"
end
end
a = A.new
# 動的にメソッドを作成
method = "he" + "ll" + "o"
# それを呼び出す
a.send(method)
メッセージ転送 (Wikipedia)
受け取ったメッセージは、仮にメソッド定義がなかったとしても自由に取 り扱うことができる。
rubyの method_missing は,メソッドがない時に呼ばれるメソッド。 メソッドの未定義を知ることができ,その処理を他のオブジェクトにま かせるのが,メッセージ転送。
proxy.rb
class Proxy
def method_missing(name, *args, &block)
target.send(name, *args, &block)
end
def target
@target ||= []
end
end
Proxy.new << 1
'end'
非同期送信
メッセージの送信と結果の受信を別々に行なう。
並列計算が可能になる。
オブジェクト指向という言葉が意味していること
https://www.infoq.com/jp/news/2010/07/objects-smalltalk-erlang
オブジェクト指向プログラミングの3つの主義は、
- メッセージ送信に基づいて、
- オブジェクト間で分離し、
- ポリモーフィズムを持つ
4 Joe Armstrongのオブジェクト指向はクソだ!
- 後から見つけた,Why OO Sucks by Joe Armstrong の訳の方がぴんときます。
4.1 オブジェクト指向が"Suck"である理由
私のOOPに対する反対意見はOOの基本的なアイデアに対するものも含まれます。 以下にそのアイデアのアウトラインと私の反対意見を述べます。
反論その1
- データ構造と機能は一緒にすべきではない
(Objection 1 - Data structure and functions should not be bound together)
オブジェクトは関数とデータ構造が分割出来ない単位としてひとつまとめにし ています。しかし、私はこれこそが基本的でかつ大きな誤りであると考えてい ます。なぜなら、関数とデータは異なる世界に存在するからです。なぜでしょ う。関数は何かを実行します。そして関数はインプットとアウトプットを持ち ます。関数の入力と出力はデータ構造であり、関数により変更されます。
- 「関数とデータは異なる世界に存在するからです」は,理由が希薄です。
- 「関数とデータは,異なるものです。」は認めます。
- データとその処理関数は近くにあって,同時に見られた方が,分かりやす いことが多いと思う。
- データだけからなるクラスがあってもいいし,インタフェースだけからな るモジュールがあってもいい。Rubyではそうなっている。
多くの言語の関数は命令のシーケンスから作られます。すなわち、「まずはこ れを実行して、次はこれを実行しなさい」という手順です。関数を理解するた めにはどのような順序でものごとが実行されるかを理解しなければなりません (遅延評価をサポートする関数型言語と論理型言語ではこの制限は緩やかで す)。
- 関数についての説明はそのとおり。
データ構造はそれそのものです。これらは何もしません。これらは本来宣言的 なものなのです。データ構造を理解することは関数を理解することよりもはる かに簡単なことなのです。
- これは違うと思う。データ構造だけを見て,データ構造を用いてできる ことを理解することは,ほんとうに難しいこと,だと思う。
関数は,入力から出力へと変換するための,ブラックボックスです。入力と出 力を理解すれば,関数を理解したことになります。でも理解したからと言って, 関数を記述できることにはなりません。
- 些細なことですが,「入力と出力を理解すれば関数を理解したことになり ます」ではなくて,関数を利用できることになるだと思います。そして, 「関数を利用できない人に,関数の中身は記述できません」だと思います。
関数は通常、コンピュータシステムにおいてジョブがデータ構造をT1からT2に 変換することの観察を通して理解したことになります。
- ここは最初,理解できませんでした。
- 「関数を書くには,複数のデータを見なくてはいけない。ある一つの型を主
にみて,書くことはよくない」と言ってるのかな。
- そうかもしれないが,。。。
適切な抽象度で見れば,関数のやってることは下記の3種 (ほんとかな?):
- 変換
- 自身 -> 自身
- 簡約
- 自身 -> 自明なもの
- 合成
- 自身 -> 高いレベルのもの
だとすると,変換や簡約は自身と一緒に記述してあると,わかりやすい。 合成は,自身の中に記述するのではなく,高いレベルのものと一緒に書 くべきだと,思えます。
入力が複数ある場合は,「どれか主になるものがある」場合や,「一纏 めとして扱うことができる」場合は,型(データ)を主に,処理の記述が でき,何をやっているのかが,分かりやすいと,思えます。
このように関数とデータ構造は全く異なるタイプの生き物です。そしてそれを 同じカゴの中に閉じ込めるのは全く持って間違っていることなのです。
- 「異なるタイプの生き物を同じカゴに閉じ込めるのは間違い」は,理由になっていません。
- 関数とデータ構造を近くに置いて,同時に見られることは,いいことです。
- 問題があるとすれば,同じデータ構造に対し,異なる操作関数からなるク ラスが沢山ある場合の冗長さかな。
「データを理解することは簡単」が考え方の違いの根本ですね,きっと。
データ駆動なのか関数駆動(こんな言葉ある?)なのかの違いですね。
関数駆動において,関数をできるだけ汎用にするためには,入力の型は, できるだけシンプルにし,入力の意味を多様に解釈・適応できることが, 関数の汎用性を高めるこになる。
オブジェクト指向では,その解釈や適応できることを,書いておきたいんだ よね。きっと。
反論その2
- すべてはオブジェクトではない
(Objection 2 - Everything has to be an object.)
「時刻」について考えてみましょう。OO言語の立場での「時刻」はオブジェク トであるべきです。でも、非OO言語では「時刻」はデータタイプのインスタン スです。例えばErlangでは「時刻」の多くのバラエティがあります。これらは とても明白で曖昧さがありません。
- 時刻を表すデータ型はあったほうがいいでしょう。自明だと思います。時 刻を表すのに整数の組み合わせをもちいたいならそうもできます。 オブジェクトであるべきかどうかの議論にはなっていません。
-deftype day() = 1..31.
-deftype month() = 1..12.
-deftype year() = int().
-deftype hour() = 1..24.
-deftype minute() = 1..60.
-deftype second() = 1..60.
-deftype abstime() = {abstime, year(), month(), day(), hour(), min(), sec()}.
-deftype hms() = {hms, hour(), min(), sec()}.
...
これらの定義はどの特定のオブジェクトにも属していません。これらはどこで
も利用できるデータ構造で「時刻」を表現しており、システムのどの関数から
でも利用することができます。
そしてどのようなメソッドにも関連していません。
- これらはインタフェース群とクラス (abstime(), hms()) )に見えるなぁ。
反論その3-オブジェクト指向言語ではデータタイプ定義はあちこちに散らばってしまう
(Objection 3 - In an OOPL data type definitions are spread out all over the place.)
オブジェクト指向ではデータタイプはオブジェクトとして定義されます。そう するとデータタイプは一箇所で見つけることができません。ErlangやCではす べての私のデータは一箇所であるinclude fileもしくはデータ辞書でみつける ことができます。でも、OOPLではこのようなことができず、データタイプ定義 はあちこちに散らばってしまいます。
- Rubyでは,class/module 単位のまとまりをつくり, 継承やincludeにより 階層を作り,require によって,必要なライブラリを記述し, 適切な抽象度で,見ることができる。散らばっているのではなく, 適切なまとまりごとに*リンク*づけられている。 一望したければ,ツールをつくればいいだろう。
この例を示しましょう。私が汎用的なデータ構造を定義したいとします。この 汎用データタイプとはシステムのすべての場所で使えるものです。
LISPプログラマであれば「わずかな汎用データタイプと多くの小さな関数がこ れらに作用すること」が「数多いデータタイプとこれらに作用する少ない数の 関数よりも良いこと」という真実を知っています。
そして、汎用データ構造としてリンクリストや配列、ハッシュテーブルがあり、 さらには時刻、日付、ファイル名などがあります。
OOPLでは私は汎用的なデータ構造を定義する際にはなにかベースオブジェクト の中から選択しなければならないというとても面倒くさいことをしなければな りません。そして、そのデータ構造はこのオブジェクトを継承して作る必要が あります。もし何か「時刻」のオブジェクトを定義したい場合、これがどのベー スオブジェクトに所属していて、それ自体、どのようなオブジェクトであるか 考えなければならないのです。
反論その4
- オブジェクトはプライベートな状態を持っている
(Objection 4 - Objects have private state.)
状態(state)は諸悪の根源です。特に関数の副作用は避けるべきです。しかし ながらプログラミング言語において状態は好ましいものではないのに関わらず、 実世界では状態は至るところに存在します。
- はい,実世界をモデル化するプログラムでは,状態を持つことは 避けら れませんね。
例えば私は銀行口座の状態、すなわちに預金残高に大いなる関心があります。 そしていつ私が入金や出金をする場合には銀行の口座が正しく更新されなけれ ばとても困ったことになります。
実世界でこのような状態が存在したとして、この状態を取り扱うためにはプロ グラミング言語はどのような仕組みを提供すればよいのでしょうか。
OOPLはプログラマから状態を隠しなさいといいます。状態は隠されてアクセス 関数を通してしか見えません。
伝統的なプログラミング言語であるCやPasalでは状態変数の可視性は言語のス コープのルールによってコントロールされます。
でも、純粋に宣言的な言語では状態は存在しないことになっています。このよ うな宣言的言語ではシステムのグローバルな状態はすべての関数の入力や出力 になりうるのです。関数型言語におけるモナドや論理型言語におけるDCGでは 「状態はあたかも関係のないように」プログラミングすることができます。に も関わらず必要な場合にはこれらのシステムの状態に完全にアクセスをするこ とができるのです。
ほんとうは「プログラマから状態を隠す」というOOPLで選択されたオプション はとても悪いものなのです。状態を公開して状態の厄介さを最小限にしようと する努力をすべきなのに、その代わりとしてOOPLではそれを隠し去ってしまっ たのです。
- よく理解できていませんが,「プログラマから状態を隠すのは良くない, OOPLだけがそうしている」という主張と読みました。
- 「隠くすことも,公開することも,できるようにしよう」という立場だと思 います。アクセスすべきものは,アクセスできるようにします。でも,アク セスする時は,その持ち主のメソッドを通してというのが,Rubyのやり方。
4.2 オブジェクトが広まった理由
オブジェクト指向が広まった理由は次のとおりだといわれています。
- Reason 1 - It was thought to be easy to learn. (簡単に学べると思われていたから)
- Ruby は簡単に学べると思う。
- Reason 2 - It was thought to make code reuse easier. (再利用がより簡単だと思われているから)
- Rubyでは,再利用が簡単だと思う。
- Reason 3 - It was hyped. (売り込まれたから)
- Reason 4 - It created a new software industry. (新しいソフトウエア産業を作ったから)
- そういう風潮もありますね。
しかし、1と2が事実であるという証拠はまったくを持って見たことがありま せん。
- 筆者は Ruby を使ったことがあるのかなぁ?
それでも実際にオブジェクト指向が広まった理由はテクノロジーに対す る逆向きの作用であると思われます。つまり、あるテクノロジーがひどすぎる と、そのテクノロジー自体が作った問題を解決するための新たなビジネスが登 場して、金儲けをしたい人たちのアイデアになるのです。実はこのことが実際 のOOPに対する推進力になっているということなのです。
- そういう風潮もありますね。
5 Strategic Choice を読もう
https://d.hatena.ne.jp/asakichy/archive を読んで,まとめをつくり,自分の理解を作りましょう。
7 構造化プログラミング
7.1 構造化プログラミング入門
構造化とは、構造のない、いわば行き当たりばったりのものを、指針に基づい た構造へと整理する作業。
オブジェクト指向も、オブジェクトという構造に整理するという1つの構造化であるといえる。
現在でも見通しの良い整理されたコードを書くにあたって、構造化プログラミングは有効に作用する。
定義
1つの入り口と1つの出口を持つようなプログラムは「順次・反復・分岐」の3 つの基本的な論理構造によって記述できる
基本手段
- 基本3構造
- 順次(連接)
- 反復(繰り返し)
- 分岐
- 段階的詳細化
- 言葉どおりに捉えれば段階的に詳細にしていくということ
- つまりトップダウンで詳細化するということ
- 基準が必要
- 凝集度
- 結合度
取上理由
- 構造化プログラミングにおけるトップダウンの機能分解には、確かに問題がある。
- この問題がオブジェクト指向の動機にもなっている。
- ただし、構造化プログラミングの実装部分のエッセンス(特に凝集度・結合度の考え方)は今でも参考
になる。
- 構造化プログラミング – 段階的詳細化 段階的詳細化 - Strategic Choice
- 構造化プログラミング – 凝集度 凝集度 - Strategic Choice
- 構造化プログラミング – 結合度 結合度 - Strategic Choice
8 パルナスの規則
> モジュールの利用者には、そのモジュールを利用するために必要なすべての > 情報を与え、それ以外の情報は一切見せないこと。
> モジュールの作成者には、そのモジュールを実装するために必要なすべての > 情報を与え、それ以外の情報は一切見せないこと。
8.1 解釈
インターフェイスと実装の分離を行い、情報隠蔽またはカプセル化を実現する。
8.2 なんで?
システムの部分同士は最小かつ明快なつながりで結ばれていることが望ましい。
- 内部を知らなくても使える(再利用)
- 利用者に影響を与えず実装を入れ替えることが出来る(保守)
9 抽象データ型 - Strategic Choice
https://d.hatena.ne.jp/asakichy/20090225/1235547089
abstract data type (ADT)
9.1 どういうこと?
- 型定義を公開できること。
- プログラマがデータ型を定義。
- インスタンスに対する操作が利用出来ること。
- 「do(data)」ではなく「data.do()」。
- 内部のデータを保護し、上記の操作のみがアクセス出来ること。
- 情報隠蔽。
- 複数のインスタンスを作れること。
- マルチプルインスタンス。
9.2 モジュールとの関連
- モジュールで情報隠蔽までは可能だった。(パルナスの規則)
- しかし複数インスタンスが作れない。
- これを満たすのがADT。
9.3 クラスとの関連
- クラスは,抽象データ型を実現するもの
- これに加えて,下記を特徴として持つ:
- 継承
- ポリモーフィズム ((s-:?))
10 オブジェクト指向の本懐 - Strategic Choice
10.1 オブジェクト指向前 – オブジェクト指向の本懐(2)・
機能分解
「構造化プログラミング」時代と呼ばれ、 機能分解(functional decomposition)の手法がとられていました。
- 問題を小さな機能にブレークダウンしていき、複雑さを回避しようとするアプローチで す。
- 図にするとピラミッドストラクチャのようになります。
- ブレークダウンされるごとに凝集度は高まり、見通しも良くなるので自然と複雑度は下がります。
しかし、ここには落とし穴がありました。
このアプローチでは、結果的に「メイン」モジュールが必要となります。
機能の組合わせとその呼び出し順を正し く制御する、大きな責任を持ったモジュールです。
こういった構造になっていると、モジュールの変更が制御できなくなります。
「他の関数」「データ」「やり取り」「順番」等、注意を払うべき項目が多 すぎるからです。
- 機能やデータを変更すると、他の機能や他のデータに影響が及び、それがま た他の機能に影響を及ぼすという修正の連鎖が「芋蔓式」に発生し、「将棋 倒し」が起こります。
その中でも特に影響が大きいのが「データ」の変更についてで、
データが機能に従属して拡散してしまっているため(方々で使っているだけ でなく、引数による上下渡り歩きも含む)、影響範囲の見極めが非常に困難 になります。
好ましくない副作用
この時代、多くのバグが、変更によって生み出されていました。
- 変更による不具合のことを「好ましくない副作用」といいます。
- 機能に注力することは、発見しにくい副作用を生み出す近道になってしまう のです。
- そして保守作業とデバッグ作業にかかる時間の大半は、バグの除去に充てら れる時間ではなく、バグの発見、および修正によって生み出された好ましく ない副作用の回避手段を考え出す時間に充てられていました。
つまり、機能分解は、ソフトウェアライフサイクルに常備されている「変更」 というイベントにおいて、例えばバグ修正時であれば二次バグ、機能追加時で あればデグレードの発生など、常に危険に晒されている手法だということです。
そして、本来使うべき開発そのものの時間ではなく、この副作用の収束に多く の時間を取られるという形で問題が顕在化したのです。
オブジェクト指向へ
変更は必ず発生するものです。
どう変わるかはわかりませんが、どこが変わりそうかはある程度予想できるの です。
そこでオブジェクト指向が登場します。
機能とデータ
書籍「オブジェクト指向入門」の中でトップダウン機能分解の弊害に言及して います。
オブジェクト指向でないアプローチでは何の抵抗もされずに、機能がデー タを支配するが、その後データが「復讐」を始めた。復讐はサボタージュ の形で現れた。アーキテクチャの基礎そのものを攻撃することによって、 データはシステムを変更に耐えられないようにした。
トップダウンの機能階層図は一見きれいですが、実はごちゃ混ぜのデータ転送 が含まれており、変更時は管理不能に陥ってしまいます。
デグレードの原因
変更して、その変更が原因で、元の機能に不具合が発生してしまうのがデグレー ドです。このデグレードが発生した時、私は「もう少し気をつけて修正すれば」 とか「もっと慎重に修正すればよかった」と反省してしまいます。しかし、そ もそもの根本原因は、修正方法よりもその設計にあることが多いという実感が あります。
そこに気が付いて、「割れ窓理論」(@書籍「達人プログラマー」)に陥らな いよう、変更に強い設計に改善していかなければなりません。
そのためのオブジェクト指向だと思っています。
10.2 オブジェクト指向黎明期の誤解 – オブジェクト指向の本懐(3)・
オブジェクト指向黎明期の誤解 - Strategic Choice
オブジェクト指向も最初から正しく活用されていたわけではありませんでした。
代表的な誤解
- オブジェクトとはデータ+操作である。
- カプセル化とはデータの隠蔽である。
- 継承は特殊化と再利用の手段である。
これらはもっともらしく見えますが、本質ではありません。
((s-:)) 実装寄りの見方なんですね。
オブジェクト指向の正しい理解
正しい理解は以下になります。
- オブジェクトとは責務である。
- カプセル化とは流動的要素の隠蔽である。
- 継承はオブジェクトを分類する手段である。
((s-:)) 概念・仕様レベルの見方ですね。
カプセル化の意味
「カプセル化、情報隠蔽、データ隠蔽」という用語は、余りにも意味が揺れて いるため、はっきりとしたことは言えないようです。
((s-:)) すべての機能をモジュールの中に閉じ込め,公開インタフェースを通 してのみ,利用可能にすること。
オブジェクト指向のウソについて
オブジェクト指向の黎明期は、その特徴について以下のように喧伝されていました。
- 現実世界をそのままモデリング(クラス化)できる。
- 実装は簡単で、属人性も排除できる。
- 差分プログラミングで簡単に再利用できる。
しかし、これらはウソないし本質ではないことは明らかです。
- モデリング
例えばコンパイラを作ろうとしたら現実にある ものは1つもでてきません。
((s-:)) いっぱいでてきますよ。文法,構文木,生成規則,…
モデリングは「捨象」です。つまり、抽象化してほとんどの部分を捨て てしまいます。「そのまま」クラスにはなりません。
((s-:)) 本質的なものだけを残すのがモデリングで,それはクラスに なります。
デザインパターンにおいて、その登場クラスのほとんどは「人工品」で、 現実世界には存在しません。
((s-:)) 人工物も一度できれば現実です。
- 実装は簡単で、属人性も排除できる
言語仕様的に便利になった部分(典型的にはC→Javaのメモリ管理)で従 来よりは品質上がるのでしょうが、
((s-:)) 簡単さは,なんといっても再利用が簡単になることじゃない かなぁ。
余りにも実装寄りの話でオブジェクト指向の本質とは全く関係ありませ んので、根拠に乏しいと思います。
((s-:)) 属人性を,メッセージングで解決することでは?
- 差分プログラミングで簡単に再利用できる
「よく似た既存クラスがあれば、それを継承し、違う部分だけを実装すれ ば再利用できる」という主張で、確かにそういった一面はあると思います。 しかしこれも実装面から見た話ですし、
((s-:)) 差のみを書くことには,積極的な意味があると思います。
- 差分プログラミングそのものはオブジェクト指向(言語)でなくても可 能です。
さらに、継承を紡いでいく拡張には設計的にも実装的にも問題点があり ます。
((s-:)) 問題の構造がそうなら,継承を紡いでいく拡張が正しいのだと 思います。
10.3 ソフトウエア開発プロセスの観点 – オブジェクト指向の本懐(4)
オブジェクト指向の考察の前提知識, マーチン・ファウラー「UMLモデリングのエッセンス」で提唱
概念(conceptual)
- 調査対象領域における概念を表現。
- 実装とは関係なく導き出される。
- 「私は何に対して責任があるのか?」
仕様(specification)
- ソフトウェアを考慮。
- 実装ではなく、インターフェイスの考慮 。
- 「私はどのように使用されるのか?」
実装(implementation)
- ソースコード自体を考慮。
- 上の2つを考えた後。
- 「私はどのように自身の責任を全うするのか?」
この観点の使い分けが非常に重要
- 概念レベルでコミュニケーションを取とると、お互いの詳細は知らなくて良 いことになります。
- 設計はまずここで考えることになります。すなわちソフトウェア以下は考慮 しません。
- すると設計アウトプットにおいて、使用者に概念をそのままにして実装を変 更できるため、結果的に使用者に対して(発生しやすい変更である)実装変 更から守ることになります。
オブジェクトとソフトウエア開発プロセスの観点の間のマッピング
ソフトウェア開発プロセスの観点とオブジェクト指向設計がよくマッチするから。 以下にオブジェクトと観点のマッピングを示す:
概念レベル
- オブジェクトは責任の集合
仕様レベル
- オブジェクトはその他のオブジェクトや自ら起動することが出来るメ ソッドの集合
実装レベル
- オブジェクトはコードとデータ、それらの相互演算処理
そしてこの観点の使い分けがわかると、既存の開発手法から「オブジェクト指 向(の本質)」にパラダイムシフトし易くなります。
10.4 オブジェクト指向パラダイム – オブジェクト指向の本懐(5)
オブジェクトとは責任である
オブジェクト指向では、機能に分解するのではなく、 オブジェクト に分解 します。
オブジェクトとは「データ+操作」ではありません。
- 決して「賢いデータ」程度の物ではないのです。
- これは実装の観点からしか見ていない, 狭いものの見 方です。
それではオブジェクトとは何か。
- オブジェクトとは 責任 です。責務を備えた実体です。
- それは 概念レベル, 仕様レベル から考察した結果導き出されるもので す。実装レベルを混ぜてはいけません。
- オブジェクトがどう実装されるか ではなく オブジェクトが何を実行するのか に着目しなければならないのです。
開発の手順
オブジェクト指向に沿ったソフトウェア開発の手順はこうなります。
- 詳細をすべて考慮することなく、予備的な設計を行う
- その設計を実装する
つまり、
- まず概念レベル(=責任)で考えることになります。
そして、責任を果たすために、他のオブジェクトが使用するためのインター フェイスを考えます。
これを 公開インターフェイス といいます。
実装をそのインターフェイスの背後に隠蔽することで、実装とそれを使用 するオブジェクトを分離しているのです。
実装レベルで考えているだけだと、結局機能分解の時と同じ問題が発生します。
- つまり、変更から守られないということです。
- 差分プログラミング的な、誤解されたオブジェクト指向もこの範疇に入ります。
一方、概念レベルでコミュニケーションをはかり、別のレベルで(実装)要求 を遂行する、という風に分けて考えると、
- リクエストする側は何が起こるかの概略だけ知っていればよいことになります。
- つまり、その概略(責任・インターフェイス)をそのままに、実装詳細の変 更から、リクエスト側を守ることができるということです。
補足
変更はいつするのか?
書籍「達人プログラマー」DRY原則の説明の中
メンテナンスとは「バグの修正と機能拡張であり、アプリケーションがリ リースされた時から始まるものである」という考えは間違いです。
プログラマーは常に「メンテナンス・モード」であり、理解は日々変わっ ていくものです。
設計やコーディング中でも新たな要求が発生するため、メンテナンスと開 発工程は分けて考えられるものではなく、メンテナンスはすべての開発工 程を通じて行う日常業務なのです。
つまり 変更は常時 ということです。
変更に本当につよいのか?
最初はなかなか実感が湧きませんでした。
書籍のサンプルには,「仕様変更」や「追加要求」がないから。
「デザインパターンとともに学ぶオブジェクト指向のこころ」を読んで実感で きた。
10.5 オブジェクト指向技術 - オブジェクト指向の本懐(6)
オブジェクト指向の「見方」はわかりました。
次はどうやって実現するかの「手段」部分です。
クラスとは
オブジェクトの共通する作業やデータを クラス に持たせる。 クラスは以下の要素を含む:
- オブジェクトが保持するデータ項目
- オブジェクトが実行出来るメソッド
- データ項目やメソッドにアクセスするための方法
型としてのクラス
抽象データ型の一つの表現方法がクラス, 抽象データ型は以下の特徴をもつ:
- 型定義を公開できること。
- プログラマがデータ型を定義。
- インスタンスに対する操作が利用出来ること。
- 「do(data)」ではなく「data.do()」。
- 内部のデータを保護し、上記の操作のみがアクセス出来ること。
- 情報隠蔽。
- 複数のインスタンスを作れること。
- マルチプルインスタンス。
継承の用途
ある型のグループを包含するような汎用の型が必要性となる
- 汎用の型が 抽象クラス*( *基底クラス )と呼び,
- それを継承している型を 具象クラス と呼ぶ。
抽象クラスは、それが表現している概念を具体化したクラスの実装を まとめることができる。
つまり、継承は オブジェクトの分類 に使用する:
- 抽象クラスによって関連のあるクラス群に名前を割り当てる方法が与えられ、
- 関連のあるクラス群を1つの概念として扱えるようになる
継承の問題点
「継承は特殊化と再利用の手段である」というのは本質ではない。
問題が起こる例
図形で5角形を表現するPentagonクラスがあるとします。
継承を使って「縁」機能を持つPentagonBorderを作成します。
- 以下のような不具合が発生します:
- 凝集度が低下する可能性がある
- Pentagonの責任にBorderは関係ない。
- 再利用の可能性が低下する
- 縁機能ロジックが他の図形で再利用出来ない。
- 変化に追随できない
- 違った観点の変更に対応出来ない。
- 次に「網掛け」機能が必要になったら、クラスの組合わせが爆発してくる。
- 凝集度が低下する可能性がある
- 継承はかつて実装的側面で語られることが多かったといいます。いわ ゆる「差分プログラミング」と称して推奨された 特化の継承 にはこのような問 題点もあったわけです。
継承に関する多くの問題を起すキーは 責任 という概念だと思います。
- オブジェクトは「責任」であり、
- さらに責任とは「責任をもった者同士の委譲である」といいます。
- 継承は同じ責任内で働くため、委譲をうまく取り扱えません。
カプセル化とは
カプセル化は、オブジェクトが自らのことに対して責任を持ち、必要のない物 は見せない、という事です。
カプセル化はあらゆる種類の隠蔽を意味しています。例えば以下のようなこと も含んでいます:
- 派生クラス
- ポリモーフィズムにより、実際の具象クラスを知らなくても良い。
- 「型のカプセル化」(抽象が具象を隠してる)といえる。
- 実装
- 実装する側は、インターフェイスが決まっているので、呼び出し側 を気にしないで変更出来る。
- 「メソッド(実装)のカプセル化」(メソッドの実装を隠せる)といえる。
- 設計の詳細
- 使用する方から、その詳細を気にしなくても良いようにする。
- 「メソッド(使用)のカプセル化」(メソッドの実装を気にしない) といえる。
- 実体化の規則
- 別途実体化専門の役割がいて、使用する側は気にしなくても良い。
- 「生成のカプセル化」といえる。
- サービス
- アダプタオブジェクトの背後の何かを隠し、実際に動作しているサー ビスクラスを使用する側は気にしなくて良い。
- 「オブジェクトのカプセル化」といえる。
オブジェクト指向技術の目的
オブジェクト指向技術を使うとき重要なのは「変更に強いソフトウェアを作る」 という目的意識です。
「変更に強いソフトウェアを作る」には、流動的要素をカプセル化します。
そこ以外の部分を再利用することができます。
オブジェクトの変遷
- 分析・設計時は責任を考えながらオブジェクトを考え、
- ソースコードではそれがクラスになり、
- 実行時にはそのクラスのインスタンスとなります。
- クラスのインスタンスはオブジェクトとも言いますので、ややこしいです。
継承のポテンシャル
継承はパワフルで、その種類も豊富です:
- 「オブジェクト指向プログラミング入門」では「継承の形態(7.3)」で8種 類の継承が、
- 「オブジェクト指向入門」では「継承の使用(24.5)」で12カテゴリの正し い継承の使い方が紹介されています。
今の私は、様々な情報から
- 「継承のようなクラス間の静的な関係より、オブジェクト間の動的で柔軟な 関係の方がよい」
- 「役割を継承でつくるとクラスが爆発する」
- 「多重継承なんて○○○」など「継承<委譲」と洗脳されています
が、継承もしっかり理解して使えば、思っている以上に強力な武器なのか もしれません。
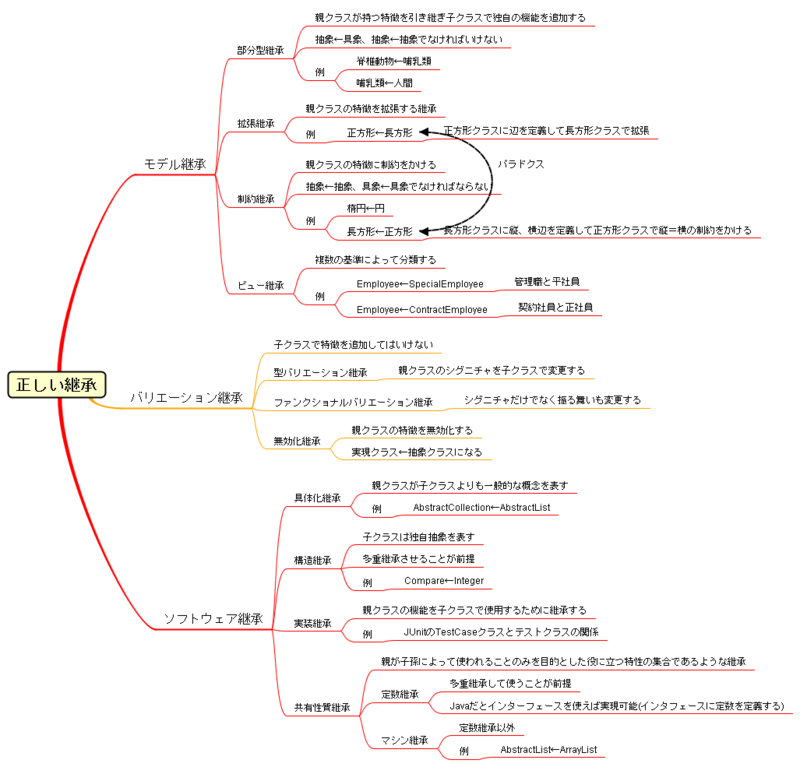
継承の種類 継承の種類 - A Day In The Life
継承の方法を12種類に分類している
- モデル継承
- 部分継承
- 拡張継承
- 制約継承
- ビュー継承
- バリエーション継承
- 型バリエーション継承
- ファンクショナルバリエーション継承
- 無効化継承
- ソフトウェア継承
- 具体化継承
- 構造継承
- 実装継承
- 共有性質継承
- 定数継承
- マシン継承
マルチプルインスタンス
データ項目をオブジェクト毎に保持し、メソッドは共通に使用できる仕組みは マルチプルインスタンスが実現しています。
10.6 オブジェクト指向分析 – オブジェクト指向の本懐(7)
共通性/可変性分析 (commonality/variability analysis)
クラスを抽出していく方法。
- 問題領域の「どこ」が流動要素となるのかを識別し(共通性)、
その後、それらが「どのように」変化するかを識別します(可変性)。
それには
まず「ファミリ構成員」を探します。
これが共通性です。
そして次に構成員がどのように違っているかを明らかにします。
これが可変性です。可変性は共通性のコンテキストの中でのみ意味を持ちま す。
つまり、
- 問題領域中の特定部分に流動的要素がある場合、
- 共通性分析によってそれらをまとめる概念が定義できることになり、
- これが抽象クラスです。
この後、
可変性分析によって洗い出された流動的要素が
具象クラスです。
共通性/可変性分析と観点とクラスの関係
「共通性/可変性分析」は
- 「ソフトウェア開発の観点」と
- 「クラス階層」にあてはめることができます。
AbstractClassは、
- これらのオブジェクトが行わなければならないこと(概念上の観点)に着目 することで、それらの呼び出し方法(仕様上の観点)を決定することができ ます。
ConcreteClassは、
- これらのクラスを実装する際、正しい実装と分割が可能になるよう、APIは十 分な情報の提供を保証しなければなりません。
「仕様上の観点」は、
- 共通性/可変性分析どちらの観点も含んでいることにな ります。
仕様上の観点と概念上の観点の関係
- 仕様上の観点によって、ある概念に存在するケースすべてを取り扱うため のインターフェイスが洗い出せます。
- つまり共通性によって、概念上の観点が定義されます。
仕様上の観点と実装上の観点の関係
- ある仕様が与えられた場合、その特定ケース(可変性)における実装方法 を決定することができます。
動詞/名詞抽出作戦
オブジェクト指向黎明期、要求仕様の文章から「動詞」と「名詞」を抽出し、 それを元にクラスを設計していた。
これは要求仕様に(=現実世界に)全てのクラスが埋まっているわけではな いので、当然うまくいかないことになります。
((s-:)) 完全ではないけれど,とっかかりには最適な方法だと,僕は思って いる。
要求仕様に完全網羅性は期待できませんし、自然言語で書かれていて、かつ その書式で変更されていくものなので、これを基に設計をするのは労多くし て功少なしです。
((s-:)) では何を基に?
「オブジェクト指向入門」での抽象クラスを見つける方法についての言及:
抽象を見つける方法は、知的発見(いわゆるユリイカ、そのための確実な 方法は存在しない)の過程で見いだすか、あるいは誰かがすでに解決策 を見つけている場合には、その人の抽象を再利用するかである。
より確実である後者は、まさにデザインパターンのことを言っているのでは ないでしょうか。
10.7 オブジェクト指向の本懐 – オブジェクト指向の本懐(8)
オブジェクト指向の本懐
複雑さに勝ち、かつ 変更に勝つ ことです。
- 変更を考慮する設計アプローチがオブジェクト指向の本質です。
変更を考慮する:
- 変更「内容」を正確に予測しようとせず,
- 「どこに」変更が発生するかを予測する
- その変更地点が 流動的要素
- 流動的要素 を考慮した設計アプローチ
具体的なアプローチ法は、GoF本で紹介されている以下の原則:
- 実装を用いてプログラミングするのではなく、
- インターフェイスを用いてプログラミングしてください。
- クラスの継承よりもオブジェクトの集約を多用してください。
- 何を流動要素とするべきかを考察してください。
このようにデザインパターンの原則がオブジェクト指向の本質に近しくなっ ています。
デザインパターンのテーマもやはり:
- 「設計変更を強いる可能性のある物」が何かを考えるのではなく
- 「再設計をせずに何を変更可能にするのか」を考えることです。
- デザインパターンはオブジェクト指向上達のショートカットと言っています。
オブジェクト指向のメリットをデザインパターンで釣り上げることができ るのです。
まさに邦題通り「オブジェクト指向のこころ」は「デザインパターンで学べ」 ということです。
書籍「Code Complete」での 流動的要素への準備の手順
- どのように(How)変わるかではなく、
- どこが(Where)変わるのかを特定し、
- 分離し、囲い込む
11 オブジェクト指向設計原則 - Strategic Choice
12 プログラミング原則 Unix思想 - Strategic Choice
13 ソフトウェア開発の真実とウソ - Strategic Choice
ohttps://d.hatena.ne.jp/asakichy/20131007/1381097627
14 ソフトウェア開発原則一覧 - Strategic Choice
15 七つの設計原理 - Strategic Choice
16 漏れのある抽象化の法則 - Strategic Choice
17 オブジェクト指向プログラミングとは
17.1 プログラム言語とは
記述のための要素
- 値と定数
- データ構造体
- 型と演算
- 変数と代入
- 文と流れ
- 関数(手続き)
- 定義
- 呼出し
- スコープ
- モジュール
実行するということ
- コードインタープリタ
- 環境
- 実行の流れを保存するスタック
- 名前を解決する束縛
- 静的か動的か
メタプログラミング
- プログラムを生成するプログラムをつくること
17.2 WikiPedia.search("オブジェクト指向プログラミング")
特徴
- 情報隠蔽
- 多相性
- 動的束縛
- 継承
17.3 僕の考え
- モジュール
- メッセージパッシング
- 差をプログラムする
17.4 Ruby オブジェクト原理主義
- 純粋オブジェクト指向
- プログラム可能なものは全て,オブジェクト
- クラスもオブジェクト
- 実行はすべてメッセージパッシングで起こる
- オブジェクトは実行の場